"11% of organisations reported definitively having a security incident, 20% reported no incidents, and 27% preferred not to answer. However, the most common response was unsure with 41%"
Cloud Security Alliance
Overview
So, you’ve decided to embrace Cloud, perhaps through a Cloud first approach for applications which don’t fit a software as a service (SaaS) model and instead you need to leverage a wide range of platform as a service (PaaS) and infrastructure as a service (IaaS), services. Along the way you have established a foundation or landing zone in one or more Cloud Service Providers (CSPs), you have an agreed shared responsibility model and a finance process to fund usage. Everything is in place for your minimum viable product (MVP) and you are now ready to let development teams consume the CSP services! For several weeks your development teams begin building services and everything is quiet. You decide to check-in with the teams involved and gather feedback before opening Cloud to more teams. The summary looks something like this:
Development Teams
We can build quickly and are ready to release into production.
We have used lots of different services, but we need some help supporting them in production.
We have a few issues where each of our environments is different.
Cloud Platform Team / Cloud Centre of Excellence (CCoE)
We are already seeing utilisation of 50+ services which we didn’t anticipate.
Costs are growing a lot quicker than we had expected.
Security Team
Reviewing the configuration of the services deployed there are many security controls not met.
Data seems to be stored without encryption and is publicly accessible.
Role permissions are over permissive.
Network controls aren’t used correctly.
Does the above sound familiar? Often the balance of security and empowerment isn’t right from day one, but it’s extremely important to recognise and address before things escalate out of control and security incidents occur. Let’s take a step back and re-visit a couple of the key benefits you were trying to realise by moving to Cloud:
Innovation - We want our teams to run with ideas and fail fast in the pursuit of additional business value.
Time to market - The time it takes from idea to a working product or service should be as quick as possible to ensure we stay ahead of the competition.
These benefits should be slightly rephrased in order to ensure that security (job zero) is reflected:
Innovation- We want our teams to run with ideas inside a safe and secure environment, where they can fail fast in the pursuit of additional business value. Security responsibilities are clear, and feedback is fast when things aren’t secure.
Time to market - The time it takes from idea to a working product or service should be as quick as possible, while ensuring that the correct security controls and governance processes are followed to prevent security incidents, ensuring we stay ahead of the competition.
So, there are some key words to focus on in those revised benefit statements, such as; 'safe', 'secure', 'responsibilities', 'feedback', 'governance', 'prevent' and 'incidents'.
The natural response to those terms is that companies will look to overlay existing governance processes and security controls into the Cloud operating model. Now whilst that can work if you have an efficient and Cloud ready set of processes and controls, in most cases the reality is that by introducing the existing approach you will succeed in compromising the original benefits of innovation and time to market. In order to address these items in a more scalable approach that aligns with the revised benefit statements, we first need to address the following.
Without the right skills across teams consuming cloud, security and agility will often fail. There should be a robust training plan in place and teams should be skills assessed before using CSP services. Often by providing developer sandboxes (spend limited) and Cloud training pathways this can be mitigated with the correct investment.
Existing culture and ways of working within an organisation should be reviewed, ideally with a look to move into a DevSecOps approach where possible. This shift in responsibility should also include some level of devolved security rather than siloed security elements which sit outside of teams and the Cloud initiative.
While a shift to DevSecOps may take some time, at minimum a trust but verify approach should be taken to ensure that teams are fulfilling their responsibilities and that security assurance is in place.
Ok so 'how do we do this the right way?' I hear you say! The answer 'Enablement and Shift Left'.
So, what does that mean? and how does it work?
Enablement – The process of making someone able to do something, or making something possible.
So, in the context of Cloud this is about allowing development teams to do what they need. As talked about before, this means letting them build and innovate, but with a level of safety and security built-in to that way of working. Teams will need to know what they should and shouldn’t be doing and will have the skills and knowledge on how to make compliant changes to progress services towards production. There are several ways to achieve that, and this article will go into a few of those.
Shift Left – Introducing security checks and work during the development phase. The goal is to ensure that the codebase is designed to be secure from the start, rather than checking for security issues at the end of the process.
Again, in the context of this article this aspect looks at how to give development teams a feedback loop as early as possible in their development lifecycle. The idea here is to prevent unsecure services from ever getting deployed, let alone making it into production. Enabling teams to correct issues quickly without human involvement where possible.
Barriers to Enablement
Enablement and shift left are not without their challenges though. To achieve your desired state of working, it’s likely you’re going to have to overcome barriers and solve some problems. You can’t simply implement shiny new tools and suddenly arrive at the enablement panacea. It would be nice if it were that easy! In reality, it’s quite hard.
Shift left is not about tools, it’s a cultural framework. Having all the relevant tools can’t drive you to the culture required to shift left. Having the correct culture in place is what will drive you toward the shift left approach. The tool selection and implementation will follow.
People will be the key to your success or failure, with that in mind here are some things that you might need to address when planning the roadmap to a new way of working. You may have people in your teams who have:
Resistance to changing ways of working, particularly things that have been so for years.
A lack of willingness to cooperate with other teams, particularly if they are used to being in a silo.
A perceived lack benefits for the work involved.
No desire to think about security because that’s for the Security Team.
All these things will slow you down and everyone needs to be brought on board so you can all ride the train to shift left, no one should be left behind.
Greater cooperation between teams will be required when developing applications so that when code is ready to be released it’s already in its secure form without the need to consider how to secure it during deployment. Without this cooperation we end up with distinct development and operations units, away from the DevOps goal.
The challenges aren’t just in adopting a shift left approach though, there are also challenges in operating the approach. Shift left isn’t going to be any good if your applications are deployed with a secure configuration which is then altered five minutes after deployment and not noticed until the next deployment (for some applications, this could be weeks and months). You’ll need some way to either enforce configuration so that it cannot be changed or quickly detect the drift and remediate in a timely manner. It’s possible your entire deployment cycle needs to change.
Is it worth the hard work to overcome these challenges?
The answer to that will become clear, especially once you’ve read a bit more about what can happen should you not have a secure deployment of your applications and infrastructure.
A recent survey by The Cloud Security Alliance found nearly a third of organisations still manage cloud security using manual methods, though in our experience it’s a much higher proportion. In many organisations, ownership of cloud security posture was not well defined. If this sounds like your organisation, you’re not alone.
Misconfiguration doesn’t have to be so obvious as an unsecured S3 bucket, it could be using default credentials on publicly facing databases, leaving admin accounts active for employees who have left or permanently leaving what was supposed to be a temporary firewall rule in place. Sound a bit too obvious? It’s not.
Data breaches are more common than many people realise and many never make the news. You can discover if you have been the subject of a data breach by going to https://haveibeenpwned.com/ and entering your email address. You might be surprised! This writer entered his email addresses and low and behold, a couple of data breaches as a direct result of misconfiguration.
In October 2019, researchers identified an unprotected Elasticsearch server holding 1.2 billion records of personal data.
In February 2019, the email address validation service verifications.io suffered a data breach. The breach was due to the data being stored in a MongoDB instance left publicly facing without a password and resulted in 763 million unique email addresses being exposed.
In November 2019, the website for Indian Rail left more than 2 million records exposed on an unprotected Firebase database instance. The exposed data included 583k unique email addresses alongside usernames and passwords stored in plain text.
This list isn’t exhaustive, but it shows how real misconfigurations are and even things that are simple to remediate can remain undetected until the risk becomes a breach. The potential impact varies from a slight service outage with no lasting consequences, to a data breach resulting in loss of reputation and it being a revenue or share price affecting incident.
Now we’ve covered where you don’t want to be, it’s time to explore where you should want to be. That place is having a well-defined and structured policy as code environment where security has been shifted to the left. It’s time to start integrating.
Integrating shift left into your processes
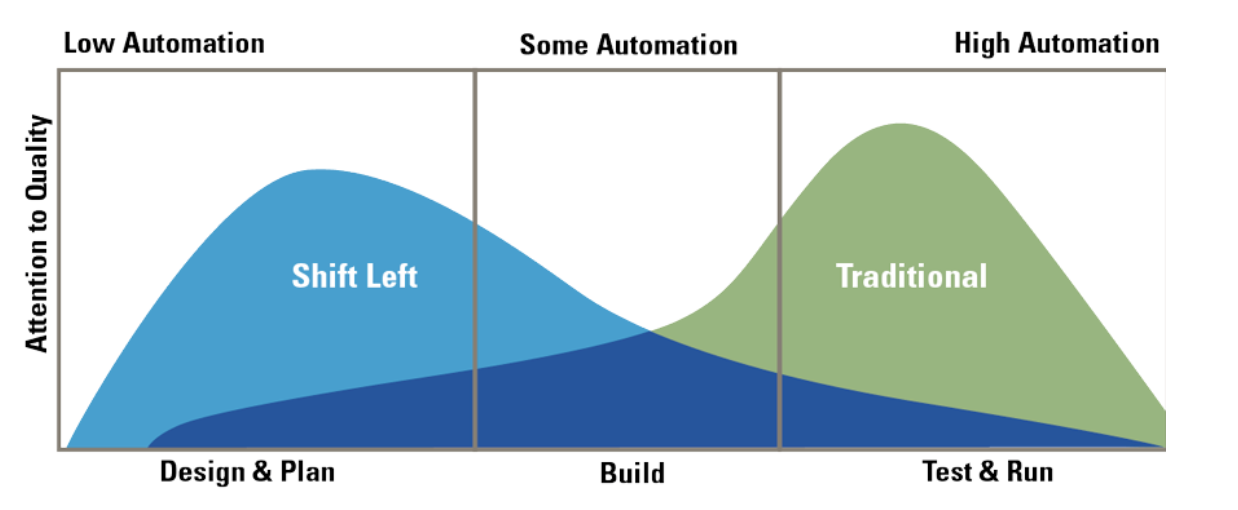
The diagram below shows the traditional approach of development, with the bulk of the focus on quality of software (including security), being in the testing and operational side of the release. Here you can visually see the literal shifting left of the focus on security to the designing and planning phases of the lifecycle.
Shift left within the software development lifecycle
The operational side of the development is highly automated, and it is possible to operate in this way because of the investment in quality during the design and planning stages. One example of an automated approach to in-life operations is continuous compliance.
Continuous Compliance
Continuous compliance involves the ability to define your configuration and have tools running to continually assess your implemented configuration and respond to drift by reverting your implementation to match your desired configuration in as near real time as is possible.
This process involves various stages:
Define- define your configurations in code
Detect - by continually assessing, detection of misconfigurations can occur in near real time
Remediate - misconfigurations can be instantly corrected after detection occurs (though consideration needs to be given to IaC and conflicts to avoid a perpetual change cycle where the two methods overlap)
Audit - record detections for any manual interventions and trend analysis
Cloud providers do provide some offerings in order to ensure your estate stays within your specified configuration.
Azure
Azure provides Azure Policy to cover those four areas above.
Azure Policy evaluates resources against policies that can be both out the box and user defined. You can configure your policies to respond to configuration outside of policy scope in the following ways:
Audit only- record the anomaly but do not remediate, no changes are made to the infrastructure
Remediate - the configuration will be changed to match your desired policy
Deny - if a resource is being deployed or altered, which would result in the configuration being outside of policy, the request can be denied so no changes are made
AWS Config is the offering from Amazon with which you can audit changes within your AWS environment and act upon creation or update events. Unlike Azure Policy which sits as an inspection and enforcement gate prior to resource creation, AWS Config acts on in-life changes. These changes can be inspected by one or more Config Rules which determine if a resource is compliant or non-compliant and if any response (remediation) should take place to correct the configuration. AWS supply a catalogue of managed rules and conformance packs for standard resource security checks, and additional rules and remediations can be authored to check other configurations and take appropriate action.
If you have multiple AWS accounts, you’re able to use an AWS Config Aggregator to unify compliance information into a single nominated account, or AWS Security Hub to deploy standard rule sets into AWS Config, which can then give visibility and benchmark information against industry standards such as CIS and PCI to help simplify the management overhead and provide a single interface into the posture of your estate.
AWS Service Control Policies (SCPs) are another technology that can be used inside an AWS Organization. An AWS SCP is a type of policy which can limit effective permissions for what resources can be created, and any conditions for a given resource type. These policies are enforced prior to resource creation, and so are a preventative control like Azure Policy. SCPs are attached at different levels of the AWS Organization hierarchy to create different effective permissions based on business needs, such as environment types or business units. Policies can be combined in a single SCP to cover many different scenarios such as ensuring a tag is present on resources created or ensuring all S3 buckets are created with encryption enabled. You can find other scenarios here
Generally, SCPs and AWS Config should both be implemented, with preventative coarse-grained elements covered by SCPs, and detective and responsive elements handled with more specific AWS Config rules to provide a level of end-to-end coverage.
Policy as Code
Policy as Code is the idea of writing business policies (and controls) in a high-level language, which can be interpreted by both humans and machines, in order to automate policy decisions within the developer workflow. This approach embodies 'shift left' by providing fast feedback to teams early in the development lifecycle for services and infrastructure which don’t conform to established policy. By writing policies in a machine-readable format, standard development practices around version control, automated testing and automated deployment can be adopted.
This process involves various stages:
Define- Create your policies as code using a domain-specific language (DSL) for the required tooling.
Deploy- Inject the policies and tooling into the development lifecycle.
Audit - Collect evidence for audit and compliance views.
Technologies
There are many technologies which are well established in this space, and far too many to cover in this article. Here are the main three that we feel have a good level of maturity to suit production use cases.
Open Policy Agent (OPA) is an open source, general-purpose policy engine. OPA, unlike other tools, looks at enforcement of policies across the entire IT stack not just development pipelines. It has a rich set of integrations with Terraform, Kubernetes, Envoy and many more where it can be called to make reliable policy decisions prior to deployment and in-life. OPA policies are written in a language called Rego which allows you to express policies over complex hierarchical data. It can be deployed in three distinct ways.
As a standalone binary
As a centralised policy server exposing a restful API
As an integration point (plugin/sidecar)
Airwalk has published some articles explaining how OPA can be used:
Sentinel is Hashicorp’s Policy as Code framework which can be used across most of the Hashicorp family of products, but most often with Terraform to provide a CSP agnostic policy enforcement layer for Infrastructure as Code (IaC). Sentinel is able to inspect a Terraform plan for compliance against defined policies within a Policy Set before permitting the deployment of infrastructure to the target environment.
We have published a detailed example in the following article:
Checkov is another agnostic framework primarily aimed at the IaC space, but it does have some support for other providers too. Checkov is intended to be consumed via the CLI rather than a REST API or embedded workflow. This allows Checkov to be used in any standard development pipeline or via pre-commit hooks.
Integrating Policy as Code
Once you get to the point of selecting a technology that fits your needs and you have authored a set of initial policies, the next step is to recognise value from Policy as Code. This will very much depend on the maturity of the organisation in terms of where to start but here are the possible methods to do that. Note: these will differ depending on the tooling selection.
Method 1 - The quickest method is to publish the required policies into a shared repository such as GitHub, and to create a set of developer guidance on how to consume them. This will usually be a case of development teams adding the tool into their local development environment and pulling the repository contents alongside. They can then pass code to the policies where it will be evaluated, and they will receive CLI feedback on any non-conforming resources/configurations. The method can be extended into the developer commit process via the use of pre-commit hooks, ensuring fast feedback.
Method 2- Tooling and policies (shared repository) are added into existing pipelines by development teams based on guidance supplied. Gates are created to automatically verify code against the policies, and to fail the pipeline if issues are detected. This implementation will be undertaken by each team across their pipelines, which will likely be across different CI/CD technologies.
Method 3 - A set of prescriptive pipelines for end-to-end deployments are created and published by a central team which include the required Policy as Code gates aligning to required controls, along with the collection of any audit information. Teams consume these pipelines in a standardised way (as a service). Teams are unable to bypass or amend the pipelines and their access to production environments is removed for any deployment activity. Instead, only the standard pipelines are able to deploy into the environment to ensure consistency and prevent unapproved changes from occurring.
All of these methods offer some value, but assurance and attestation can only really be achieved when utilising the third method, as it removes any uncertainty around the governance approach and ensures consistency, versioning and attestation for audit purposes which isn’t possible in a distributed manner (methods 1 and 2).
Service Catalogue
The final approach that can help with enablement is via the creation of a Service Catalogue. The concept here is for an SME team, usually the CCoE to provide a set of IaC templates in an agreed way for development teams to consume. The products in the catalogue (templates) should be built to encompass best practices and adherence to security policies, so that when teams utilise items from the catalogue they will already comply with these additional requirements. This approach helps to constrain the ways services are used into repeatable patterns, which if done correctly can be pieced together like Lego. For example, individual resources can be created such as a security compliant S3 bucket, or a combination of services into something of greater value, such as a multi-AZ RDS deployment with standard logging and auditing or an egress filtering solution. Rework time is heavily reduced for teams consuming the catalogue, instead they can focus on business value and innovation. To maximise the benefits of using a Service Catalog approach, you will want to ensure that you are also adopting a service whitelisting approach in parallel, as this will help to prevent teams from using too many services prior to the correct guard rails and products existing, as it can be very difficult to retrofit such a mechanism after the event.
Test - Perform deployment tests to ensure all security checks are compliant
Publish - Advertise product templates with semantic versioning to teams
Deploy - Developers will deploy products into their CSP environments
There are many ways to build and expose a capability like this to your development teams. We will go into a couple of these below.
Technologies
Terraform Cloud and Terraform Enterprise
Terraform is often adopted by organisations as the IaC tool of choice due to its support for multiple providers and its opensource community. A key feature of Terraform is the creation of modules. Modules allow you to define reusable components which can be authored and checked into a source control repository such as Github. Once under source control a release version can be created (semantic version) which teams can begin to reference in their IaC code base, effectively pulling in the versioned modules they require for deployment. A central set of repositories can be created in this way to form a Service Catalogue where community contribution within the organisation can help reduce load on a central function producing all of the required products. An existing catalogue of modules exists via registry.terraform.io where these can be stored and accessed publicly, alongside submissions from software vendors and other organisations; however, in most cases a more suitable location would be in a private registry which is a feature of both Terraform Cloud and Terraform Enterprise.
AWS Service Catalog
CloudFormation is another IaC tool primarily for AWS but has over time introduced support for other platforms and services via the use of resource providers. The idea with CloudFormation is the same as Terraform above, in that a set of standard IaC templates would be authored and tested. The key difference though is that AWS have extended support for CloudFormation through several of their other services. AWS Service Catalog is one of those services and it provides a ready-made hosting solution for products (templates) and portfolios aggregating one or more of those products. Once created the portfolios can be shared with other AWS accounts in the Organization for the purpose of deployment, versioning and deprecation. Service Catalog exposes a standard location for teams to browse the available products within their accounts as well as the ability to deploy, terminate or update them as CloudFormation stacks either via the console, CLI or API; there is also support for deployment of several products from the Catalog inside a wrapper CloudFormation template to add an additional level of consistency across environments
Azure Managed Applications
Azure Managed Applications provides a simplified deployment process for preapproved solutions. You can define templates and applications to ensure they adhere to the standards and governance that meets the requirements of your organisation. You can then publish your offerings internally as a service catalog to be consumed by members of you organisation.
Integrating a Service Catalogue
Having a catalogue of products (templates) is a great starting point, but the reality is that it will take time to author enough products in order to cover an entire set of services and solutions. If you have time to do that prior to allowing further development great, if not you will want to incrementally shift teams over to using this approach as items are added, to reduce the burden on development teams maintaining all aspects themselves; development teams can help to raise pull requests for services or solutions they’ve already created to speed up the process too.
Summary
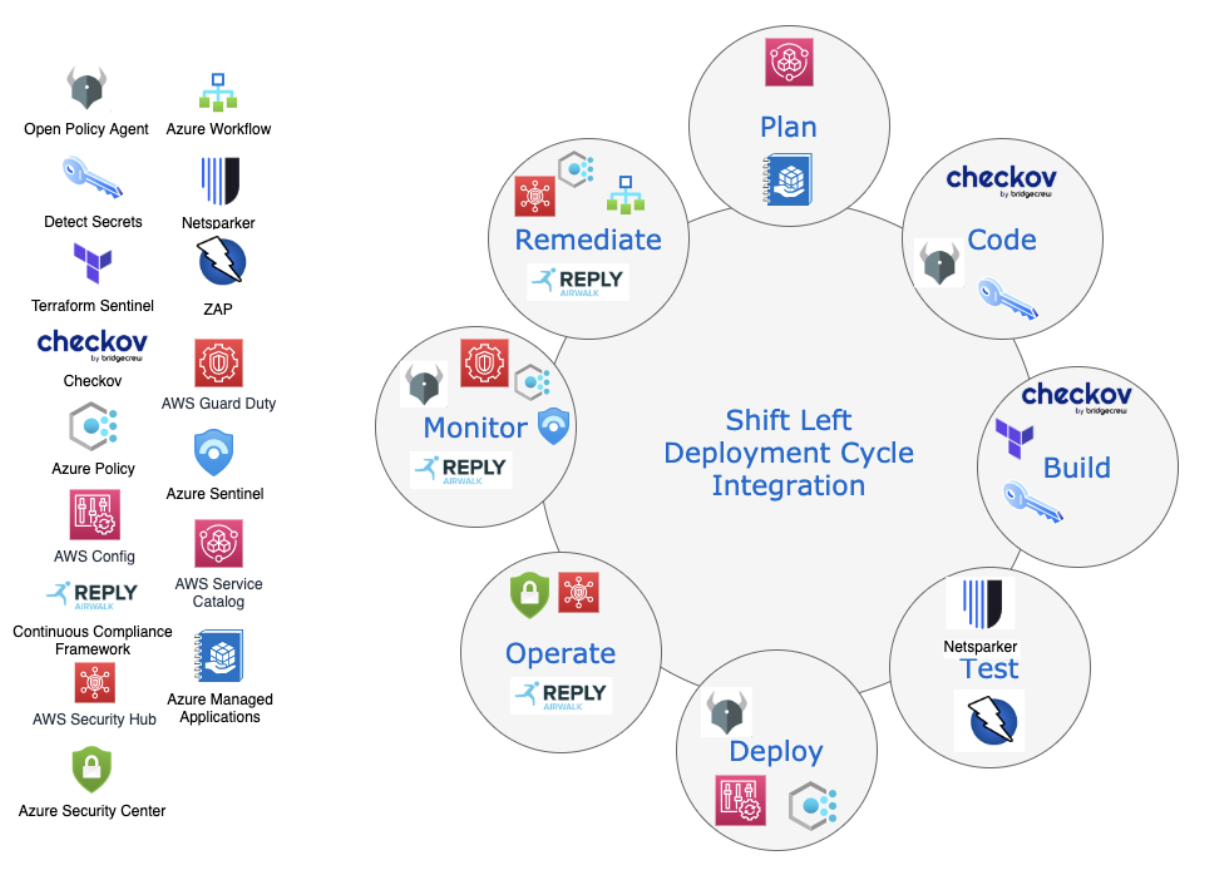
Integration of shift left components may occur at all stages of your typical deployment cycle. Below is a diagram showing an example of such a lifecycle along with some existing tools that can help improve your security posture.
Tool integration points within a deployment cycle
Policy as code tools can slot into each stage to form a multifaceted approach. During planning, you’re able to leverage service catalogues to provide assurance from the beginning, and if authoring your own code or templates, there are tools to help validate and secure that code before deployment.
Post deployment in the operational phase, there are several options available to monitor and remediate vulnerabilities in an automated and timely fashion to ensure you stay compliant.
As you can see from the approaches discussed, there are multiple ways to help enable teams to deliver services in a secure and right-first-time manner. Now the question you face is which of these options should you implement? Well, the answer is to start with the approach that makes the most sense for your organisation. There is no right answer here but generally you will want to start with an incremental approach by selecting at least one of the methods in this article, with a gradual transition into making use of them in a complimentary fashion. The following graphic should help to illustrate that utilising the approaches in a complementary way can lead to a measurable reduction in residual security risk and the time it takes your teams to move services into production by improving developer productivity.
Once you reach stage four, your teams will be operating in a highly efficient manner with minimal security risks. They would consume products from the available catalogue, make all changes to environments via code and deployment pipelines where Policy as Code checks will validate that all applicable security controls have been met, along with any evidence for the purpose of attestation and audit. Additional in-life compliance will be handled via preventative and responsive controls where there are items which can’t be addressed during the pipeline phases and finally continuous compliance via detective controls helps to assure the business for all deployed resources. Enablement and shift left is now a reality, teams contribute and receive fast feedback early in the development lifecycle.
This won’t be the end of the journey, there will always be the need to introduce net new controls and tweak policies and products, but you will have reached a point of continual review and improvement.
Here at Airwalk Reply we work with many heavily regulated organisations which are at differing maturity levels, where we are enabling them to realise the benefits outlined in this article. Alongside the work we do in this space, we also offer solutions such as our Continuous Compliance Framework which can help in the detective and responsive controls category.
Contact us if you’d like to discuss this article further with Matt and Neil or if you want to know more about our Architecture and Security offering.
.jpg)